
I started using Polars and DuckDB in late 2021. It was immediately apparent to me that these libraries would soon be at the heart of the of data science ecosystem. Since then the popularity of the libraries has grown exponentially.
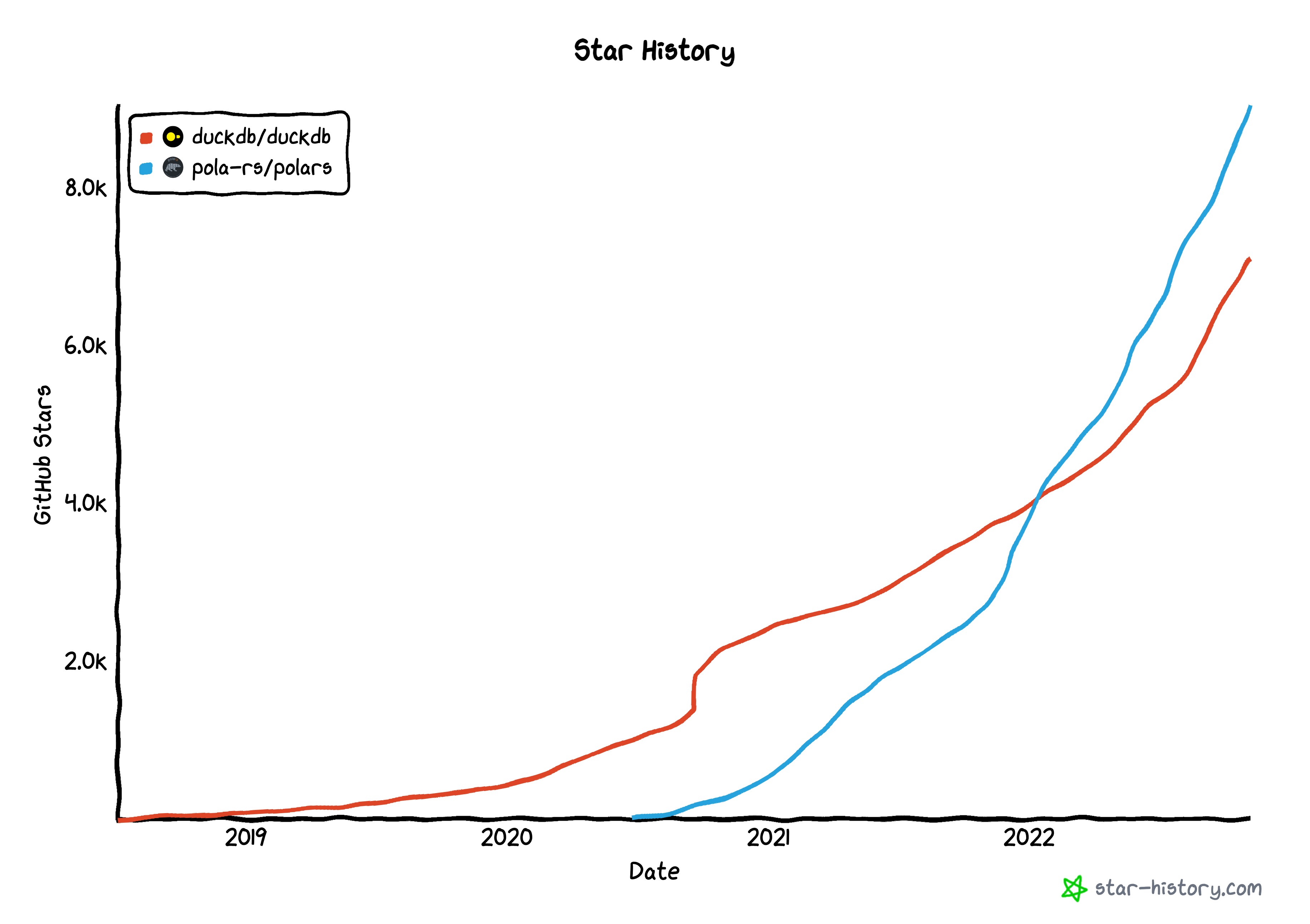
In this post I make some predictions about where we’re headed in the data science world in the next few years and why we’re heading there.
This post is here to test my prognostic abilities. But I’ve also written it to trigger debate about what the key trends are and to help data scientists think about the skills they should develop in the coming years.
Caveats
- This is written from the perspective of someone whose work has traditionally started with exploratory data analysis in Pandas and then been productionised in a serverless function. The production stage might involve an ML model but might also be a set of defined rules and regexes.
- My experience also encompasses working as a research scientist where you run large-scale analysis on a cluster without any serverless production stage.
If your perspective is different please get in touch on twitter/linkedin to share your thoughts!
Prediction 1: Polars and DuckDB replace Pandas as core tools for tabular data
Polars and DuckDB will become the standard tools for data analytics in Python as they offer such a jump in performance compared to Pandas. The transition has started with users who feel most performance pressure but they will become standard as the ecosystem around them develops.
The advantages of these tools aren’t just in how fast they can compute, however. The expression syntax of Polars is a much more natural fit for describing data transformations than the equivalent in Pandas. Both libraries apply automatic query optimisation that avoids the increasingly tedious manual optimisation of Pandas code. Both libraries also handle parallelisation and larger-than-memory data without myriad other dependencies.
I see Polars and DuckDB becoming a duopoly rather than one of them replacing Pandas as a monopoly. Although the functionality of these two libraries has a lot of overlap there will be some people who want a tool like DuckDB that has more trappings of a relational database while others do not.
Prediction 2: Arrow will be the core technology of the data science ecosystem
Apache Arrow is a format to represent in-memory data. Arrow is designed to be language agnostic and libraries that implement this format have emerged in many languages.
Polars is built directly on a Rust Arrow library called Arrow2. DuckDB isn’t built on Arrow but can do zero-copy reads from Arrow data.
Arrow will displace Numpy arrays at the core of the data science ecosystem for tabular data. This means that visualisation, machine learning and other libraries will accept Arrow objects inputs. As Arrow allows zero-copy data exchange these libraries will be able to ingest data directly from dataframes without much of the wasteful data copying that happens at present.
As Arrow allows easier inter-process communication we will also see convergence of data science tools such as fitting R models within a Python script.
The pace of change on this front has been slower than the adoption of Polars and DuckDB. However, the pace of change is increasing. For example, XGBoost models now accept Arrow Tables as input while the Huggingface Datasets library uses Arrow for its local caching system.
Prediction 3: Rustification
In the decade of so of the data science boom day-to-day work in my orbit has been dominated by either dynamic languages like Python or languages that use just-in-time compilation like R and Julia. Compiled languages like C and C++ are used under the hood for Python extensions or the internals of DuckDB but few data scientists work directly with them.
I predict that Rust will be the first pre-compiled language to be commonly used by data scientists (without displacing Python and R as the main languages). The adoption of Rust among data scientists will be driven by Polars where users see that the jump from using Python to the Rust API is relatively small - and much smaller than the jump from using Pandas to C!
We will also see more libraries built on top of Rust with APIs in Python and R. In particular, I think we will see a widely-used Scikit-Learn alternative written in Rust and built on Apache Arrow.
The benefits of Rust have become apparent to me in the months I’ve been working on Polars. The performance gains over Python are massive and paralellisation has been reliably managed. However, it is the modern tooling system around Rust such as Cargo for managing dependencies that make it a much less intimidating prospect for Python developers to adopt than older languages. One factor in my decision to focus my efforts on Polars over DuckDB was that I am excited about learning Rust in a way that I’m not about learning C++.
What about GPUs?
I recently described Polars as the fastest data science tool on the planet. One respondent correctly pointed out GPU-based libraries like cuDF are faster. However, there are lots of additional costs to using GPUs from the cost of the GPU itself to additional cloud instances to manage.
GPUs will continue to grow in popularity for data processing but will not become the standard approach in the next few years. As Polars and DuckDB make more efficient use of multi-core CPUs with built-in parallelisation and vectorised instructions the cost-benefit trade-off of GPUs will only make sense for power users.
What’s next?
I’ve got skin in the game with these predictions. I quit my job last year to develop the first online course in Polars. In fact, I think it is the first online course in any part of the Arrow ecosystem. I believe that anyone who gets good training in Polars and Arrow will be ahead of the game for years to come.
Learn more
Want to know more about Polars for high performance data science and ML? Then you can:
- join my Polars course on Udemy
- follow me on bluesky
- follow me on twitter
- connect with me at linkedin
- check out my youtube videos
or let me know if you would like a Polars workshop for your organisation.