
Published on: 5th September 2022
Boolean filters in Polars?
This post was created while writing my Up & Running with Polars course. Check it out here with a free preview of the first chapters
Scan some kaggle competitions and you’ll see that Boolean masks are a common way to filter Pandas dataframes.
However, read the Polars docs and they beg you not to use this approach. Instead they recommend using the .filter method.
Why is this?
I thought it was partly for performance reasons. But with a 10 million row dataset the boolean mask and .filter queries give similar results (and both are much faster than Pandas.
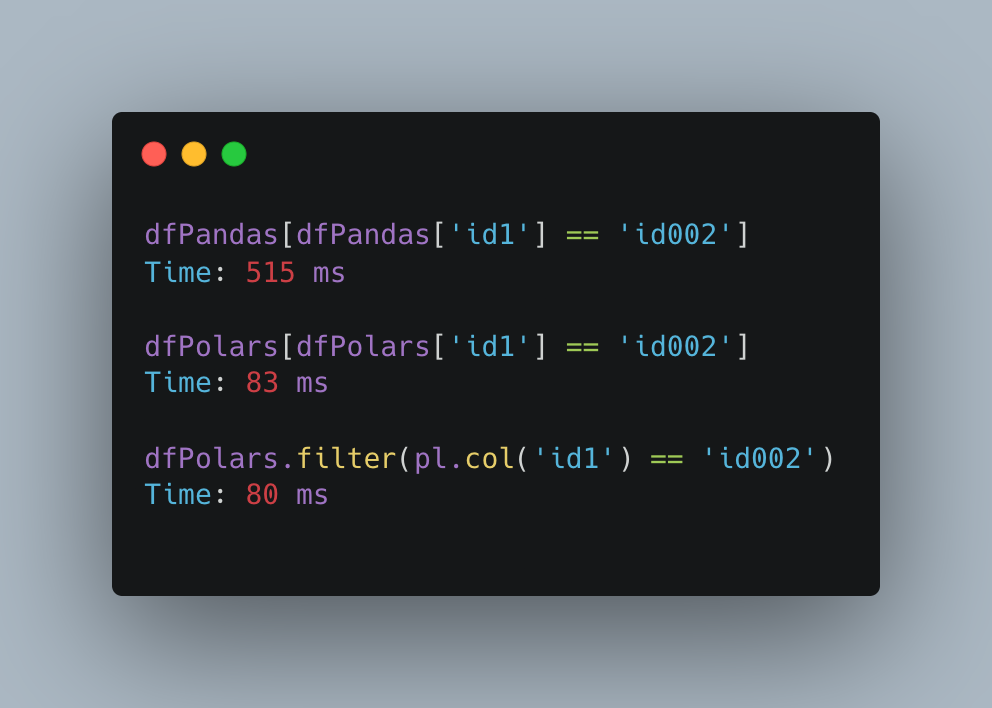
The real reason for using .filter is to take advantage of lazy mode and query optimization.
With Pandas you need to read the full dataframe into memory before you can apply a filter.
In lazy mode in Polars you can build this filter into your full query - including which data you read from the CSV.
In this case it leads to Polars being 14x faster.
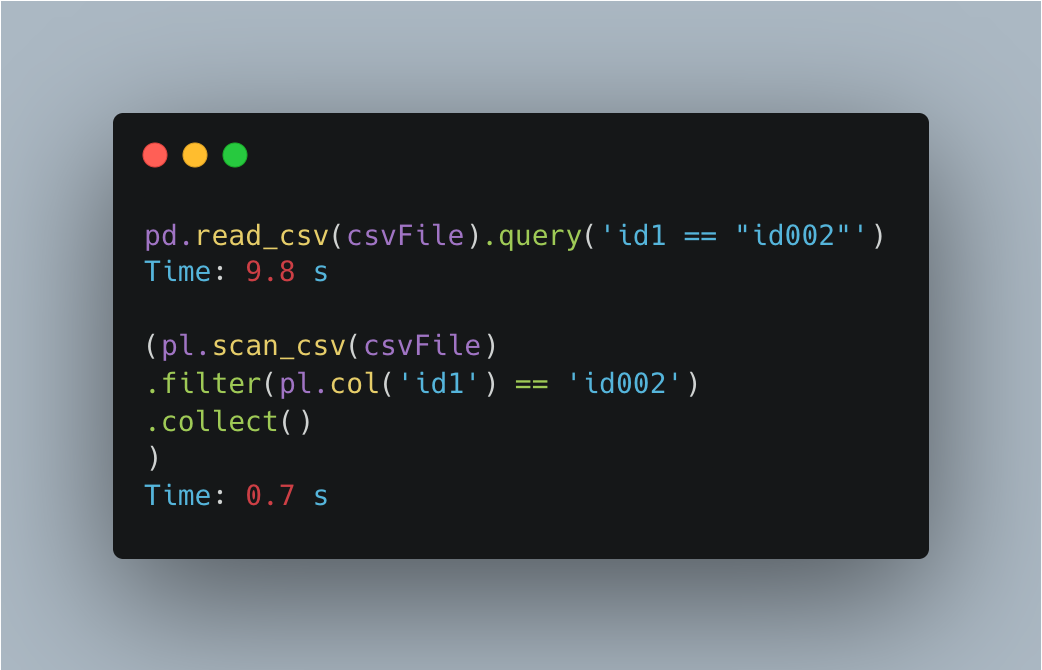
Overall, Polars recommends using .filter instead of boolean masks because it helps to push more and more into the query optimizer.
If you are trying Polars but not using these methods then give them a go and compare timings to your existing code - I think you’ll be surprised!
Learn more
Want to know more about Polars for high performance data science? Then you can:
or let me know if you would like a Polars workshop for your organisation.