
Published on: 5th September 2022
Loading from a database with Polars
This post was created while writing my Up & Running with Polars course. Check it out here with a free preview of the first chapters
On some projects the challenge is that you’ve got a big dataset but only want to look at well-defined subsets of the data at any given moment.
One powerful way to approach this is to take advantage of databases and their ability to sub-select data.
Create a local database
First you take your dataset and write it to an SQLite DB with Pandas. Then create an index on the column you want to define subsets on.
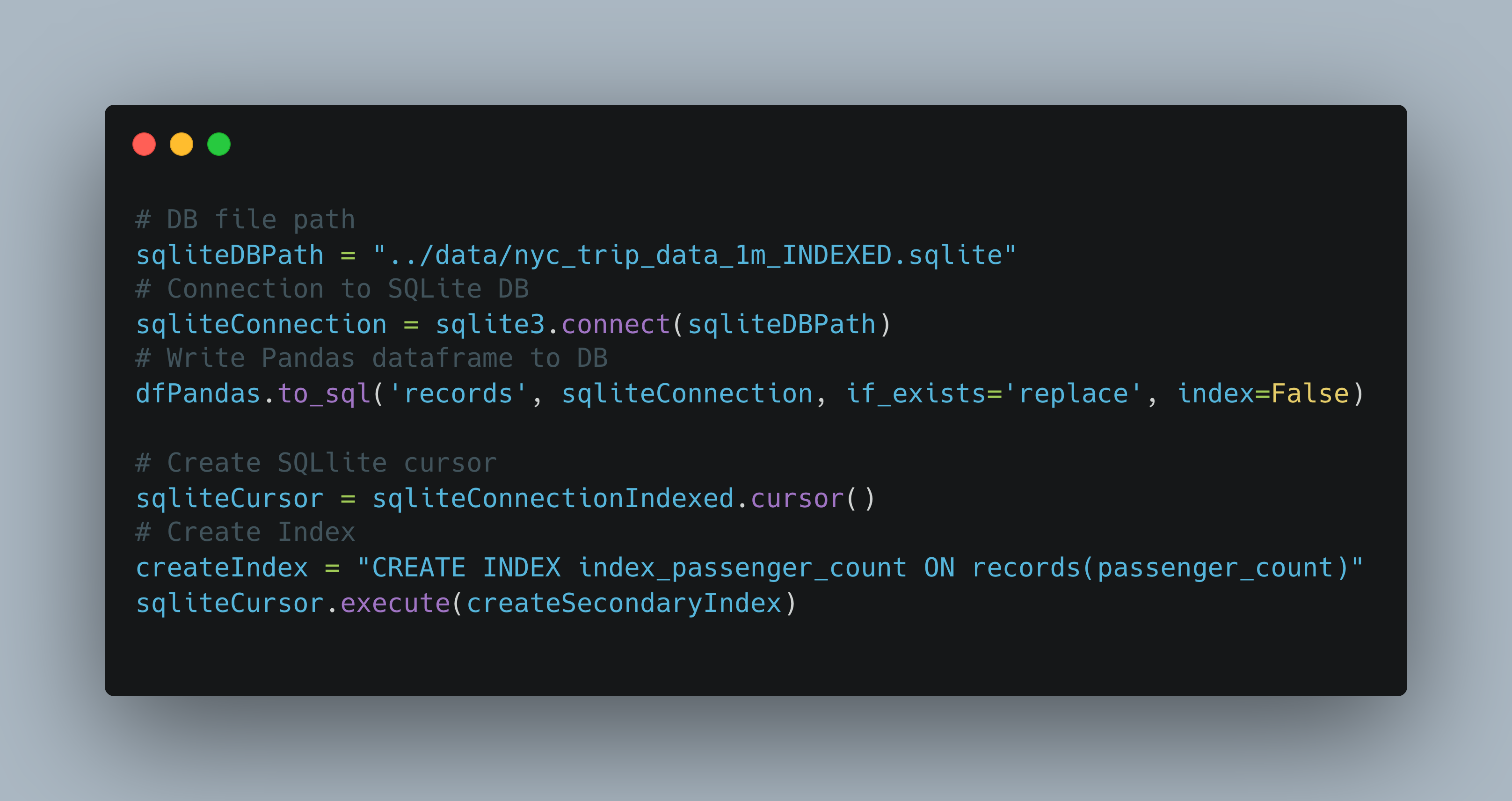
In this case we only do it on the passenger number column, but you can do more advanced indexes on multiple columns.
Read from the database
Then you use Polars and connectorx - the fastest way to read from a database in python.
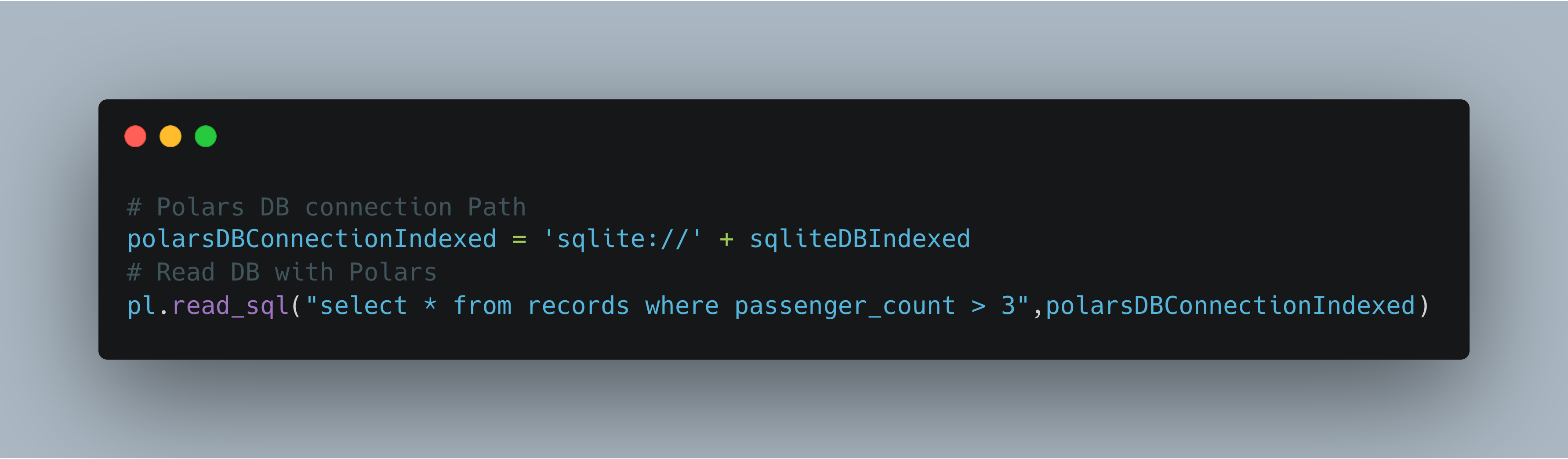
Add a where clause into your SQL statement to choose your subset. The data will be filtered in the DB before being read into the dataframe.
Reading from a database isn’t as fast as using IPC or Parquet files.
However, the DB approach is very powerful when you are selecting small parts from large datasets. It’s also handy when you just need to work with a DB!
Follow me if you’re interested in learning more about high performance data processing in python!
Learn more
Want to know more about Polars for high performance data science? Then you can:
or let me know if you would like a Polars workshop for your organisation.