
Published on: 5th September 2022
IPC files in Polars
This post was created while writing my Up & Running with Polars course. Check it out here with a free preview of the first chapters
A 1000x speedup with simple workflow changes - even I’m surprised by that!
I switched from Pandas to Polars and converted the dataset from CSV to IPC format. However, we need to dig a bit deeper to understand what it means in practice.
What are IPC files?
Firstly, what is this IPC format? It’s an on-disk format that mirrors how Apache Arrow stores data in memory. It’s also known as Arrow format or Feather format.
IPC is very fast to read because it requires minimal serialisation. But there’s more to IPC, because IPC in Polars supports memory-mapping.
With memory-mapping Polars doesn’t read the file into memory - it knows where the data is on disk.
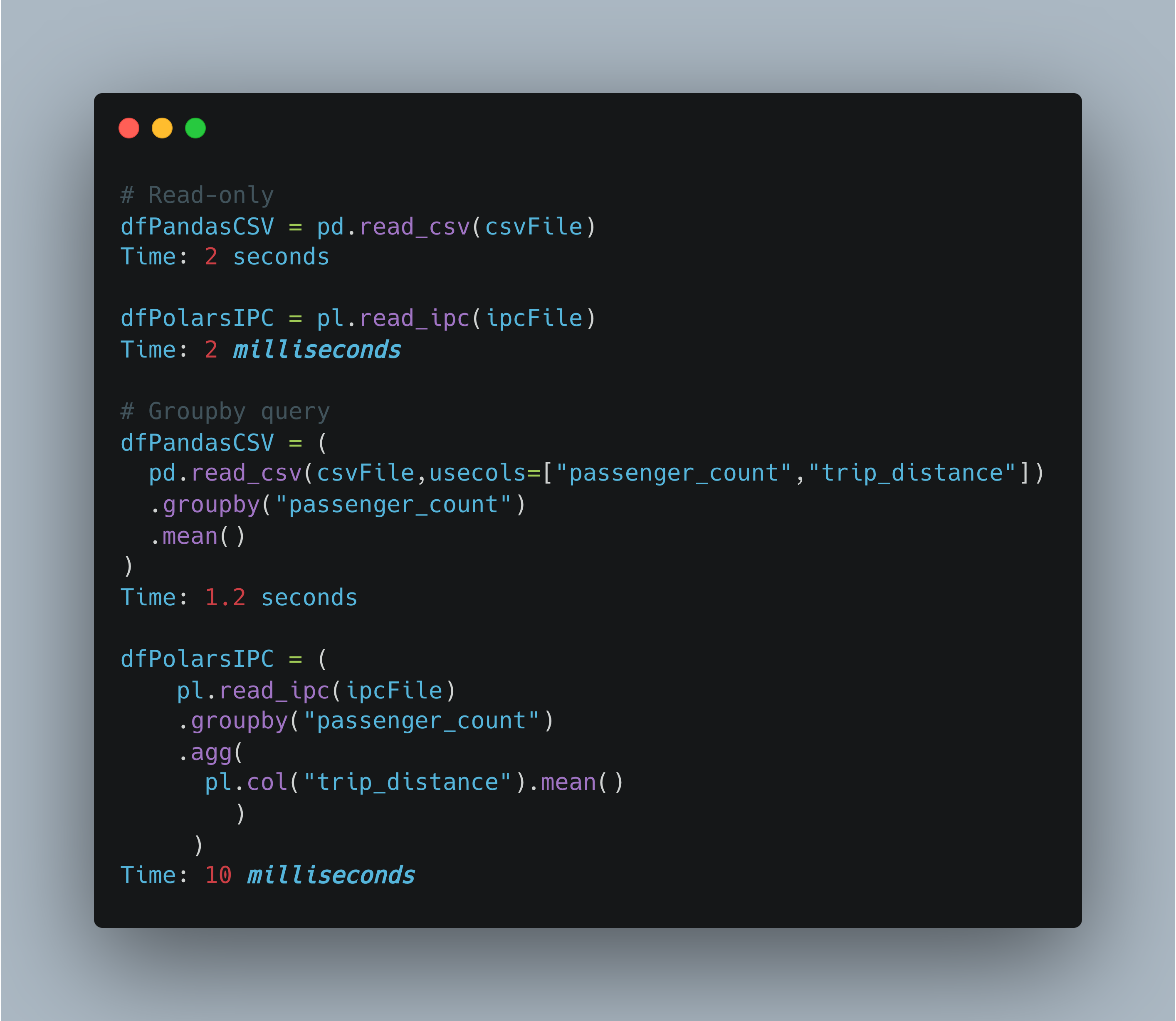
This makes pl.read_ipc in Polars fast as it doesn’t have to read the data into memory. But not being in memory will then be a drag on performance compared to read_csv.
Testing a full query
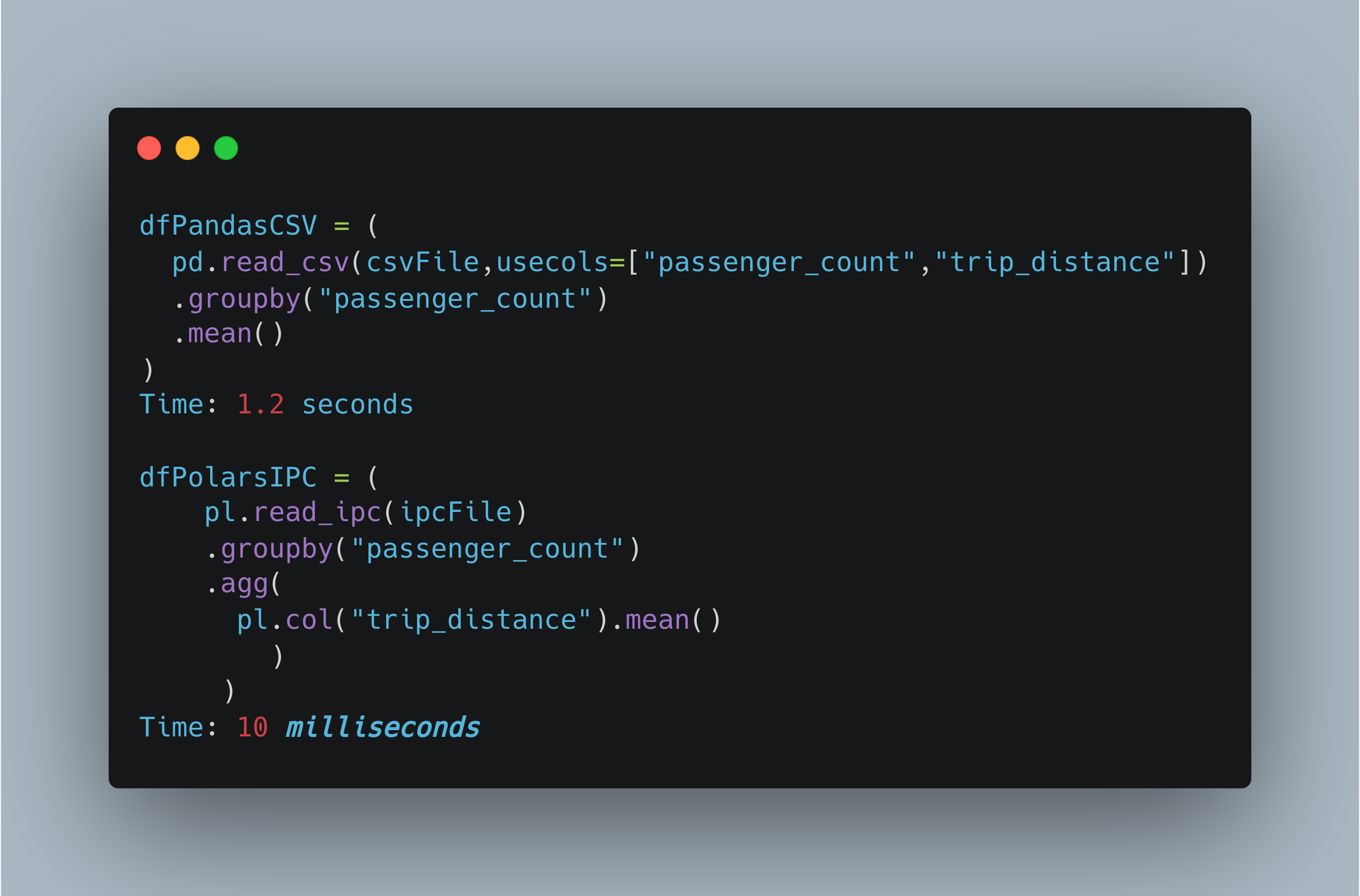
We can test the full performance in practice by doing a full query - in this case on NYC taxi data. We get the mean distance by number of passengers.
So in practice: Polars with IPC is 100x faster than Pandas with CSV. Not bad.
Pandas also supports IPC with pd.read_feather of course. Polars is about 5x faster than Pandas in this comparison.
The main drawback of IPC is that the file size can be larger than CSV. There are many use cases where more storage for faster queries is a good tradeoff though.
In any case with IPC Polars can also process larger-than-memory files by streaming the calculations.
I think the IPC format is underused, especially when you need to read big files from a local file system or fast cloud connection - think for example what you can do in a Streamlit app with 10ms latency!
Thanks to Ritchie Vink and Kyle Barron who helped me to understand how this all works.
Learn more
Want to know more about Polars for high performance data science? Then you can:
or let me know if you would like a Polars workshop for your organisation.